New & Noteworthy
SGD Newsletter, May 2026
May 27, 2026
About this newsletter:
This is the May 2026 issue of the SGD newsletter. The goal of this newsletter is to inform our users about new features in SGD and to foster communication within the yeast community.
Contents
- Join Us at Yeast Genetics Meeting 2026
- Introducing BLAST Search for SGD at the Alliance of Genome Resources
- Textpresso Literature Search: New Login System
- Naming Your Newly Characterized Yeast Gene: A Guide to SGD Gene Nomenclature
- Alliance of Genome Resources News
- microPublications – Latest Yeast Papers
- Upcoming Conferences & Courses
- The End of PomBase?
- In Memoriam: David Botstein
Join Us at Yeast Genetics Meeting 2026

The Yeast Genetics Meeting is the premier meeting for people studying various aspects of eukaryotic biology in yeast, the major model organism for understanding human cell biology and human disease mechanisms. This international meeting has a 40-year history and is held every two years in North America.
The SGD team will be at this year’s Yeast Genetics Meeting at Asilomar, and we’d love to connect with you! We’re hosting a workshop and will have a table and posters throughout the conference.
Workshop: Unlocking Yeast Biology with SGD: Tools, Data, and Discovery
Monday, June 15, 2026 | 3:30 p.m. – 5:30 p.m.
Learn how to leverage the Saccharomyces Genome Database (SGD) to accelerate your research. This workshop will highlight key tools, curated datasets, and practical strategies for exploring gene function, pathways, and genomic data in Saccharomyces cerevisiae. Whether you’re a longtime SGD user or new to the resource, you’ll discover ways to make the most of SGD’s comprehensive data and analysis tools.
Stop by our table and posters during the meeting to chat with the SGD team, share your feedback, ask questions, or learn about the latest updates to SGD and the Alliance of Genome Resources. We look forward to seeing you there!
Introducing BLAST Search for SGD at the Alliance of Genome Resources

We’re excited to announce the launch of a new BLAST service for Saccharomyces Genome Database (SGD) data, now available at the Alliance of Genome Resources. This release marks another significant milestone in our ongoing effort to migrate SGD services and data to the Alliance platform, ensuring continued access to essential yeast genomics tools within an integrated, multi-organism framework.
What’s New
The Alliance BLAST service provides researchers with powerful sequence similarity search capabilities against SGD datasets, maintaining the functionality that the yeast research community has relied on for years while benefiting from the Alliance’s modern infrastructure and cross-species integration.
Key Features
- Comprehensive SGD datasets: Search against the complete S. cerevisiae genome, including coding sequences, proteins, and genomic DNA
- Familiar BLAST functionality: All standard BLAST algorithms (BLASTN, BLASTP, BLASTX, TBLASTN, TBLASTX) are supported
- Enhanced performance: Leveraging the Alliance’s updated infrastructure for faster search results
- Cross-species exploration: Seamlessly explore homologs across other Alliance member databases
Part of a Broader Migration
This BLAST service is part of our comprehensive strategy to transition SGD resources to the Alliance of Genome Resources. This migration ensures that:
- SGD data remains accessible and well-maintained for the research community
- Users benefit from integration with data from other model organisms
- Resources are consolidated on a sustainable, collaborative platform
- The yeast community gains access to enhanced comparative genomics tools
Visit the Alliance of Genome Resources to access the new services for SGD BLAST and Fungal BLAST. The datasets will be familiar to longtime SGD users.
We remain committed to supporting the yeast research community through this transition. Additional SGD tools and features will continue to migrate to the Alliance platform in the coming months. Stay tuned for updates, and as always, we welcome your feedback.
Textpresso Literature Search: New Login System
Textpresso is a specialized literature search tool provided by SGD that allows users to search through full-text scientific articles using keywords.

It’s particularly useful for finding specific mentions of genes, phenotypes, or experimental details that might not appear in article abstracts.
Textpresso has implemented a new authentication system using Amazon Cognito as part of the ongoing migration to the Alliance of Genome Resources infrastructure. Previously, Textpresso could be used without logging in, but going forward, all users will need to create a free account through a simple self-signup process. The new system provides secure authentication while maintaining the powerful literature search capabilities researchers depend on. When you next visit Textpresso, you’ll be prompted to create an account using your email address. You’ll receive a verification code to complete the setup, and then you’ll be ready to search. Your existing Textpresso bookmarks will continue to work, you’ll just need to log in first. More information: http://textmining.textpresso.org/new-login-system/
Naming Your Newly Characterized Yeast Gene: A Guide to SGD Gene Nomenclature
Have you discovered the function of a previously uncharacterized Saccharomyces cerevisiae gene? Here’s everything you need to know about giving it an official standard name.
Understanding Yeast Gene Nomenclature
SGD maintains the S. cerevisiae nomenclature according to guidelines established by the yeast research community. These conventions ensure consistency and clarity across the field, making it easier for researchers worldwide to communicate about genes and their functions.
The Naming Rules
Valid standard names for S. cerevisiae ORFs follow a simple but important format:
- Three letters followed by a number (for example, COX2 or CDC28)
- Must be unique, not previously used to describe another yeast gene
- Should ideally reflect function when possible
This naming convention has served the yeast community well for decades, creating an intuitive system where gene names often provide immediate clues about biological roles.
How to Reserve Your Gene Name
If you’re preparing to publish work on a gene that currently has only a systematic name (like YAL037W), reserve a standard name through SGD before publication. Here’s how:

The Reservation Process
- Submit early: Reserve your gene name before you publish. A gene name reservation is valid for twelve months, which is typically enough time to write, submit, and publish your manuscript.
- Access the reservation form: Visit https://www.yeastgenome.org/reserved_name/new, or navigate from any SGD page using the purple toolbar at the top: Community > Nomenclature > Submit a Gene Registration.
- Publication makes it official: Your reserved gene name will become the standard gene name upon publication.
Best Practices for Publication
When you’re ready to publish, we recommend:
✓ Double-check the literature to ensure your chosen name is still unique
✓ Include both the ORF name and gene name in your abstract – this helps SGD and other databases find and curate your paper efficiently
✓ Verify your reservation is still active if your publication timeline will extend beyond the initial twelve-month period
Need More Information?
You can review the nomenclature conventions for yeast on our Help pages. The complete gene naming process is described in detail in our Gene Naming Guidelines.
Questions?
The SGD team is here to help! If you have questions about the gene name reservation process or nomenclature guidelines, please don’t hesitate to contact us.
Alliance of Genome Resources News
Alliance of Genome Resources – Latest Releases 9.0.0 & 8.3.0
9.0.0 Release – May 13, 2026
The 9.0.0 release includes data refreshes from each of the model organism source databases as well as various backend improvements.
Updates and improvements have been made to the following pages:
- Non-gene genome features, e.g. enhancers, TF binding sites, etc., are now represented on their own respective “Gene” pages labeled as “GENOME FEATURE”. Examples include this enhancer page and this TF binding site page
- The gene page Alleles and Variants table now has fully functional filtering for Allele symbol and Variant name
- Allele page Genomic Variant Information and (high-throughput) Variant page Summary widgets now display the relevant genome assembly, thousand comma separators for genomic coordinates (for ease of reading), and symbol hyperlinks to JBrowse for the respective variant
- Note that rs IDs for variants are no longer used to construct URLs for high-throughput variants matching the rs IDs because a single rs ID can represent multiple individual variants for which we would like to render a Variant page. Instead, HGVS.g names are used as unique identifiers in URLs to point to distinct and individual variants in a more robust manner. An example of an rs ID use on the 8.3.0 release and prior is rs864303764 which enabled a single URL in those prior releases but did not adequately represent all three individual variants that the rs ID represents. These are now represented by URLs constructed based on the full HGVS.g name for each variant: NC_000085.7:g.3684464A>C, NC_000085.7:g.3684464A>G, and NC_000085.7:g.3684464A>T (example URL: https://www.alliancegenome.org/variant/NC_000085.7:g.3684464A>C)
- Many high throughput variant insertions, deletions and indels had been mistakenly omitted from the Alliance variant data set, but have now been included for the 9.0.0 release
- This release makes available a large increase in the number of C. elegans alleles (~12K to ~1.9M) due to shifting data sources on our back end resources
- Gene page Summary widgets now display, where applicable, a gene systematic name (for fly, worm, and yeast genes) and UniProt Gene Centric Reference Proteome (GCRP) IDs, distinct from other UniProtKB IDs
- A number of significant backend changes have removed or modified existing Alliance public API endpoints. See release notes for examples.
- All “Cache Search” endpoints have been removed. See release notes for examples.
- All “Homology” endpoints have been removed (homology data can be extracted from the Orthology file on the Downloads page and endpoints for gene/orthologs and gene/paralogs). See release notes for examples.
- Other select endpoints have been removed, replaced by the updated endpoints. See release notes for examples.
- Modified endpoints are now compliant with our LinkML data model and deliver a different JSON format from previous releases. See release notes for examples.
8.3.0 Release – December 17, 2025
The 8.3.0 release includes data refreshes from each of the model organism source databases as well as various backend improvements.
Updates and improvements have been made to the following pages:
- The News page https://www.alliancegenome.org/news now includes a feed for the Alliance Mastodon account.
- The Alliance BLAST Service page https://www.alliancegenome.org/blastservice has been updated to include fly, worm, yeast, fungal, and rat BLAST services. This BLAST service allows researchers to search genomic sequences using the Basic Local Alignment Search Tool (BLAST). By entering a sequence or query, users can find regions of similarity to various genomes within the Alliance. This service supports separate environments for each of the Model Organism Databases (MODs) as well as a unified environment for the Alliance. Results provide detailed alignments and annotations to aid in your research.
- Gene page transgenic alleles tables have been updated with improved filter and sort options, and now include alleles where the focus gene plays a regulatory role in transgenic constructs.
- Gene page expression data now features enhanced sorting capabilities and clearer formatting in downloadable files.
microPublications – Latest Yeast Papers

microPublication Biology is part of the emerging genre of rapidly-published research communications. microPublications publishes brief, novel findings, negative and/or reproduced results, and results which may initially lack a broader scientific narrative. Each article is peer-reviewed, assigned a DOI, and indexed through PubMed and PubMedCentral. Consider microPubublications when you have a result that doesn’t necessarily fit into a larger story, but will be of value to others. Latest yeast microPublications:
- Wang TK, et al. (2026) A cross-species rescue by mating method to interrogate gene essentiality across the Saccharomyces genus. MicroPubl Biol. 2026 Mar 27;2026:10.17912/micropub.biology.002022. doi: 10.17912/micropub.biology.002022. eCollection 2026.
- Brown K, Singuluri H, Perkins F, Kuchin S (2026) The N-terminal α helix domain of the mitochondrial VDAC protein Por2 is dispensable for promoting the nuclear localization of yeast AMPK. MicroPubl Biol. 2026 Feb 23:2026:10.17912/micropub.biology.001040. doi: 10.17912/micropub.biology.001040. eCollection 2026.
- Ackermann LM, Ro A, Dunn B, Moore R, Doss G, Armstrong JO, Dunham MJ (2026) Using Experimental Evolution to Correct Mother-Daughter Separation Defects in Brewing Yeast. MicroPubl Biol. 2026 Feb 13:2026:10.17912/micropub.biology.001962. doi: 10.17912/micropub.biology.001962. eCollection 2026.
- Klepin S, Michalik B, Pillus L, Chik JK (2025) Mutation of a conserved anthranilate phosphoribosyltransferase active site residue supports tryptophan biosynthesis in vivo. MicroPubl Biol. 2025 Dec 15:2025:10.17912/micropub.biology.001925. doi: 10.17912/micropub.biology.001925. eCollection 2025.
- Beckwith SL (2025) Co-expression of a retrotransposon and re-targeted restriction factor impairs yeast growth. MicroPubl Biol. 2025 Nov 3:2025:10.17912/micropub.biology.001905. doi: 10.17912/micropub.biology.001905. eCollection 2025.
Upcoming Conferences & Courses
- Yeast Genetics Meeting 2026
- June 13 to June 17, 2026 –
- Asilomar Conference Grounds, Pacific Grove, CA
- Chromosome Biology and Cell States in Yeasts
- July 27 to July 29, 2026 –
- Niagara Falls Convention Center, Niagara Falls, NY
- 41st SMYTE Small Meeting on Yeast Transport and Energetics
- September 12 to September 16, 2026 –
- Chaves, Portugal
- 39th International Specialized Symposium on Yeasts (ISSY39)
- November 08 to November 12, 2026 –
- Seoul, South Korea
The End of PomBase?
Recently, PomBase learned that their grant application to the UK’s Biotechnology and Biological Sciences Research Council (BBSRC) for three years of funding was unsuccessful.

This decision places PomBase on a path to closure. Without alternative support, which at present seems unlikely, Pombase will lose not only the database but also the specialist expertise required to curate, maintain, and develop it. All three staff are funded entirely through grants; when funding stops, the resource and the knowledge behind it disappear together.
PomBase, like SGD, is a core piece of scientific infrastructure. It underpins research far beyond the yeast community, enabling discovery, reproducibility, and data integration across the life sciences. Losing it would not be a local setback; it would be a permanent loss to the global research ecosystem.
This is not just about PomBase. Essential bioinformatics resources are at risk. Other model organism databases, like SGD and Flybase, are under the same funding squeeze. FlyBase now requires support by direct fees from the community to sustain its curation. The wider scientific community must choose to sustain the shared infrastructure that drives modern biology and innovation. The contraction of funding has exposed a systemic vulnerability in how we fund biological data resources. We urge funders, institutions, and the community to recognize what is at stake. Once lost, resources like PomBase, Flybase, and SGD cannot simply be rebuilt.
In Memoriam: David Botstein

We are deeply saddened to share the news of the passing of David Botstein, a towering figure in modern genetics and a foundational force behind the Saccharomyces Genome Database (SGD).
SGD began in the early 1990s in David’s lab at Stanford University, and his vision for a rigorously curated, community-centered resource set the course for what SGD is today. His belief that carefully organized, interoperable data would accelerate discovery has guided our work from the start and continues to shape our mission.
David’s scientific impact is vast and enduring. He co-authored the landmark 1980 paper introducing the use of restriction fragment length polymorphisms (RFLPs) for human genetic mapping, a conceptual breakthrough that opened the door to finding disease genes well before whole-genome sequencing was possible. He later helped usher in the era of genome-wide expression analysis, demonstrating how systematic measurement and clustering of gene expression could illuminate cellular pathways, regulatory programs, and physiological states. Across decades, his work, leadership, and mentorship helped define the fields of genetics and genomics.
Yeast, and the global community that studies it, benefited enormously from David’s clarity of thought and sense of purpose. He championed model organisms as engines of insight, insisting that fundamental principles uncovered in yeast could illuminate biology more broadly. From the beginning, he advocated for standards, reproducibility, and open data, principles that remain at the heart of SGD. Many of the practices we still rely on, including careful literature-based curation, genotype-to-phenotype integration, and community engagement, grew directly from his vision.
David was also a gifted mentor and collaborator. He trained and inspired generations of scientists, curators, engineers, and students, encouraging bold ideas and rigorous tests of those ideas. Those who worked with him remember his incisive questions, his generosity with time and credit, and his unwavering commitment to getting the science right. His influence extends through the many people he mentored and the communities and institutes he helped build at MIT, Stanford, Princeton, and beyond.
To the SGD team, David’s legacy is personal. We have been honored to steward a resource he helped bring into being, and we remain committed to the principles he championed: accuracy, openness, and service to the community.
We extend our deepest condolences to David’s family, friends, colleagues, and the many people around the world who learned from and were inspired by him.
Note: If you wish to receive this newsletter via email, please contact the SGD Help Desk at sgd-helpdesk@lists.stanford.edu.
Categories: Newsletter
Tags: Newsletter
SGD Newsletter, December 2023
December 13, 2023
About this newsletter:
This is the December 2023 issue of the SGD newsletter. The goal of this newsletter is to inform our users about new features in SGD and to foster communication within the yeast community. You can view this newsletter, as well as previous newsletters, on the SGD Community Wiki.
Contents
- 1 Reference Genome Annotation Update R64.4
- 2 Full-text search tool Textpresso updated
- 3 Biochemical Pathways now in SGD Search
- 4 microPublications – latest yeast papers
- 5 Updates to SGD’s YeastMine data warehouse
- 6 Chemical structures now on Chemical pages in SGD
- 7 Alliance of Genome Resources – Release 6.0
- 8 SGD’s Social Media Footprint is Expanding
- 9 Upcoming Conferences and Courses
- 10 Happy Holidays from SGD!
Reference Genome Annotation Update R64.4
The S. cerevisiae strain S288C reference genome annotation was updated. The new genome annotation is release R64.4.1, dated 2023-08-23. Note that the underlying genome sequence itself was not altered in any way.
This annotation update included:
new uORFs for 3 ORFs:
8 new ncRNAs:
- SUT035/YNCC0015W
- SUT053/YNCD0033W
- SUT468/YNCD0034C
- SUT532/YNCG0047C
- SUT125/YNCG0048W
- SUT126/YNCG0049W
- SUT390/YNCP0025W
- SUT418/YNCP0026W
3 ORFs demoted from ‘Uncharacterized’ to ‘Dubious’ based on request from NCBI because they overlap tRNAs:
Various sequence and annotation files are available on SGD’s Downloads site. You can find more update details on the Details of 2023 Reference Genome Annotation Update R64.4 SGD Wiki page.
Full-text search tool Textpresso updated

SGD’s instance of Textpresso has recently been updated! Each week, SGD biocurators triage new publications from PubMed to load the newest yeast papers into the database. Once they are in SGD, those papers get indexed and loaded into Textpresso – a tool for full-text mining and searching.
This is the new part: Content updates in SGD’s Textpresso are now happening on a weekly basis, meaning you can search full text of the very latest yeast papers!
You already love Textpresso for searching full text and its other bells and whistles:
- Search results shown in the context of the full text – hits to query terms highlighted in situ
- Custom corpus creation – you can decide which papers to search
- Search using Boolean operators
- Search scope options for document or sentence
- Search location options can constrain to specific sections of papers
Textpresso can be accessed via the “Full-text Search” link under “Literature” in the purple toolbar that runs across the top of most SGD webpages. Now you can search full text of the very latest yeast papers each week!
Biochemical Pathways now in SGD Search

YeastPathways, which is the database of metabolic pathways and enzymes in the budding yeast Saccharomyces cerevisiae, is manually curated and maintained by the curation team at SGD.
This resource is jam-packed with information, but somewhat hidden from view. To make the pathways more readily accessible, some time ago we added a new section with pathways links on the relevant gene pages. Now the pathways are available in SGD Search!
The category “Biochemical Pathways” is now available, with facets (i.e., subcategories) for References and Loci. For even easier access, we also added the Pathway names and IDs to the autocomplete in the Search box, to enable quick browsing. Enjoy!
microPublications – latest yeast papers

microPublication Biology is part of the emerging genre of rapidly-published research communications. We are seeing a strong set of microPublications come through the database and are glad for this venue to publish brief, novel findings, negative and/or reproduced results, and results which may initially lack a broader scientific narrative. Each article is peer-reviewed, assigned a DOI, and indexed through PubMed and PubMedCentral.
Consider microPubublications when you have a result that doesn’t necessarily fit into a larger story, but will be of value to others.
Latest yeast microPublications:
- Bennett SA, Cobos SN, Son E, Segal R, Mathew S, Yousuf H, Torrente MP (2023) Impaired RNA Binding Does Not Prevent Histone Modification Changes in a FUS ALS/FTD Yeast Model. MicroPubl Biol 2023
- Chang S, Joyson M, Kelly A, Tang L, Iannotta J, Rich A, Castilho Coelho N, Carvunis AR (2023) Unannotated Open Reading Frame in Saccharomyces cerevisiae Encodes Protein Localizing to the Endoplasmic Reticulum. MicroPubl Biol 2023
- Chen A, Gibney PA (2023) Disruption of GRR1 in Saccharomyces cerevisiae rescues tps1Δ growth on fermentable carbon sources. MicroPubl Biol 2023
- Courtin B, Namane A, Gomard M, Meyer L, Jacquier A, Fromont-Racine M (2023) Xrn1 biochemically associates with eisosome proteins after the post diauxic shift in yeast. MicroPubl Biol 2023
- Delorme-Axford E, Tasmi TA, Klionsky DJ (2023) The Pho23-Rpd3 histone deacetylase complex regulates the yeast metabolic transcription factor Stb5. MicroPubl Biol 2023
- Garcia B, Riley KJ (2023) Saccharomyces cerevisiae NRE1 and IRC24 Encode Paralogous Benzil Oxidoreductases. MicroPubl Biol 2023
- Kowaleski SJ, Hurmis CS, Coleman CN, Philips KD, Najor NA (2023) SHE9 deletion mutants display fitness defects during diauxic shift in Saccharomyces cerevisiae . MicroPubl Biol 2023
- Runnebohm AM, Indovina CJ, Turk SM, Bailey CG, Orchard CJ, Wade L, Overton DL, Snow BJ, Rubenstein EM (2023) Methionine Restriction Impairs Degradation of a Protein that Aberrantly Engages the Endoplasmic Reticulum Translocon. MicroPubl Biol 2023
All yeast microPublications can be found in SGD.
Updates to SGD’s YeastMine data warehouse

Allele SGDIDs added to YeastMine
YeastMine is SGD’s data warehouse, powered by InterMine. We have so many templates (i.e., pre-defined queries) that provide access to so many different kinds of data.
A big area of focus for SGD and the yeast community is alleles. Alleles are different versions of genes that vary in DNA and sometimes protein sequence. Did you know that you can easily and quickly get all curated yeast allele data directly from YeastMine?
The Genes -> Alleles template returns data for one gene or a list of genes or the entire genome! Data include standard and systematic names for genes, gene name descriptions, allele names and descriptions, allele types, aliases, and references. SGDIDs for genes are included, and now SGDIDs for the alleles have been added. Previously, this query returned all of these data without the SGDIDs for the alleles. Based on user feedback, we have now made these allele SGDIDs available, so that they can be used to identify and distinguish different alleles.
Downloads files added to YeastMine
Back in the day, SGD maintained an FTP site to distribute data in various files. More recently, you have found these files in the SGD Downloads site. We have now moved these files to YeastMine:
From the YeastMine homepage, click Templates at top left. In the Filter, select ‘Downloads’ to constrain the list of templates.
The following query templates are listed under Downloads:
- Deleted Merged Features: Retrieve all deleted and merged features.
- Retrieve Functional Complementation for genes: For gene(s), retrieve information about cross-species functional complementation between yeast and another species.
- Retrieve GO Terms: Retrieve GO Terms, including name, ID, namespace, and definition.
- Retrieve SGD chromosomal Features: Retrieve genes and other chromosomal features, including IDs, coordinates, and descriptions.
- Retrieve all cross-references for all genes: Retrieve IDs for yeast gene and gene products in other databases.
- Retrieve all domains of all genes: Retrieve Proteins/Genes that have a given domain.
- Retrieve all interactions for all genes: Retrieve physical and genetic interactions for all genes.
- Retrieve all pathways for all genes: Retrieve all metabolic pathways for all genes.
- Retrieve protein properties of all proteins of ORFs: Retrieve protein properties, including pI, molecular weight, N-terminal and C-terminal sequences, codon bias, etc. of all proteins.
For help using YeastMine, please see the SGD Help Pages and our YeastMine playlist on the SGD YouTube Channel.
Chemical structures now on Chemical pages in SGD
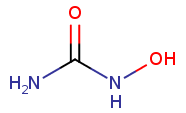
SGD curators use the Chemical Entities of Biological Interest (ChEBI) Ontology, maintained by EMBL-EBI, to describe chemicals used in experiments curated from yeast publications and displayed on SGD webpages.
You may have noticed that we have recently added chemical structures provided by ChEBI to the Chemical pages in SGD! Click the structure to zoom in, click again to zoom back out.
It’s a small detail, but we love this feature, and hope that you do too! Thanks, ChEBI!
Alliance of Genome Resources – Release 6.0
The Alliance of Genome Resources, a collaborative effort between SGD and other model organism databases (MOD), released version 6.0 in September 2023.
Version 6.0 adds new features to gene pages:
- New Paralogy section. Similar to Orthology, the Paralogy data are sourced from the DRSC’s DIOPT tool, which lets you view predictions from several tools at one time. Each table is ranked based on similarity, identity, alignment length, and a count of algorithms (methods) used to predict a paralogous match. See human HSPA1A gene page for an example.
- New Sequence Detail section. For different transcripts of the gene, you can choose to view the sequence for the gene, or its CDS, cDNA, protein, gene with collapsed introns, or genomic sequence with or without 500 bp up and downstream.
- Disease Qualifier. The qualifier describes whether a gene may be, for example, a marker_for the onset of a disease, or implicated_in the severity of a disease.
- Disease “Annotation details”. The pop-up for individual table rows has expanded to include Association, Additional Implicated Genes, Genetic Modifiers, Strain Background, Genetic Sex, Notes, and Annotation Type.
- The Download file from the gene page disease table now includes fields for Additional Implicated Gene ID, Additional Implicated Gene Symbol, Gene Association, Genetic Entity Association, Disease Qualifier, Evidence Code Abbreviation, Experimental Conditions, Genetic Modifier Relation, Genetic Modifier IDs, Genetic Modifier Names, Strain Background ID, Strain Background Name, Genetic Sex, Notes, Annotation Type, and Source URL.
- The Source column entries now link back to their respective resource webpages.
SGD’s Social Media Footprint is Expanding

Discourse, Mastodon, BlueSky – oh my! Social media is in a chaotic period, with once tight-knit communities having been dismantled and thrown into the ether. SGD feels your pain; we have been searching for our audience, waiting for the stardust to settle, coagulate, coalesce…. In the interim, in an effort to reach you, we have set up SGD outposts on various platforms:
Discourse: The Alliance of Genome Resources Community Forum brings together communities of the major model organisms – yeast, worm, fly, zebrafish, frog, rat, and mouse – in one place. Users can create accounts to post announcements and questions, and chat with other researchers in a science-focused arena. Contact SGD for an invited account, which has additional permissions.
Mastodon: We’re just getting started with Mastodon; follow SGD at @yeastgenome@genomic.social
BlueSky: We’ve also just begun with BlueSky; follow SGD at @yeastgenome.bsky.social
We will be cross-posting to the various accounts – come find SGD on these platforms and we can navigate this latest social media adventure together!
Upcoming Conferences and Courses
- TAGC2024 The Allied Genetics Conference
- National Harbor | Washington DC Metro Area
- March 05 to March 10, 2024
- 32nd Fungal Genetics Conference
- Asilomar Conference Grounds, Pacific Grove, CA
- March 12 to March 17, 2024
- 16th Yeast Lipid Conference
- Saarland University, Homburg, Germany
- May 29 to May 31, 2024
- JCS2024: Diversity and Evolution in Cell Biology
- Montanya Hotel & Lodge, Catalonia, Spain
- June 24 to June 27, 2024
- 39th Small Meeting of Yeast Transporters and Energetics (SMYTE)
- University of York, York, United Kingdom
- August 28 to September 01, 2024
- ICY2024: 16th International Congress on Yeasts
- Cape Town International Convention Centre, Cape Town, South Africa
- September 29 to October 03, 2024
Happy Holidays from SGD!
{kind=link}

We want to take this opportunity to wish you and your family, friends and lab mates the best during the upcoming holidays. Stanford University will be closed for two weeks starting December 21, reopening on January 4th, 2024. Although SGD staff members will be taking time off, the website will be up and running throughout the winter break, and we will resume responding to user requests and questions in the new year.
Note: If you no longer wish to receive this newsletter, please contact the SGD Help Desk at sgd-helpdesk@lists.stanford.edu.
Categories: Newsletter
Tags: Newsletter
SGD Newsletter, Fall 2021
December 14, 2021
About this newsletter:
This is the Fall 2021 issue of the SGD newsletter. The goal of this newsletter is to inform our users about new features in SGD and to foster communication within the yeast community. You can view this newsletter as well as previous newsletters on our Community Wiki.
Contents
- 1Protein Complex Page Updates
- 2Nomenclature Updates
- 3New links to AlphaFold 3D Predicted Protein Structure Database
- 4DIOPT Orthologs and new queries in YeastMine
- 5Alliance of Genome Resources – latest release
- 6Upcoming Conferences and Courses
- 7Gene Ontology Consortium Fall 2021 Meeting
- 8Happy Holidays from SGD!
Protein Complex Page Updates
SGD has made recent updates to our protein complex pages to improve clarity and ease of use. The new pages for each complex will have the same format as gene pages, with tabs across the top for each category of information, including a Summary page, a Gene Ontology page, and a Literature page. Just as we do for all of your favorite genes, Gene Ontology and Literature curation for complexes will be ongoing.
If you have any questions or feedback about the updates to our complex pages, please do not hesitate to contact us at any time.
Nomenclature Updates
SGD has long been the keeper of the official Saccharomyces cerevisiae gene nomenclature. Robert Mortimer handed over this responsibility to SGD in 1993 after maintaining the yeast genetic map and gene nomenclature for 30 years.
The accepted format for gene names in S. cerevisiae comprises three uppercase letters followed by a number. The letters typically signify a phrase (referred to as the “Name Description” in SGD) that provides information about a function, mutant phenotype, or process related to that gene, for example “ADE” for “ADEnine biosynthesis” or “CDC” for “Cell Division Cycle”. Gene names for many types of chromosomal features follow this basic format regardless of the type of feature named, whether an ORF, a tRNA, another type of non-coding RNA, an ARS, or a genetic locus. Some S. cerevisiae gene names that pre-date the current nomenclature standards do not conform to this format, such as MRLP38, RPL1A, and OM45.
A few historical gene names predate both the nomenclature standards and the database, and were less computer-friendly than more recent gene names, due to the presence of punctuation. SGD recently updated these gene names to be consistent with current standards and to be more software-friendly by removing punctuation. The old names for these four genes have been retained as aliases.
Legacy gene names
| ORF | Old gene name | New gene name |
|---|---|---|
| YGL234W | ADE5,7 | ADE57 |
| YER069W | ARG5,6 | ARG56 |
| YBR208C | DUR1,2 | DUR12 |
| YIL154C | IMP2′ | IMP21 |
New systematic nomenclature for yeast genes not in the reference genome
For many years, a widely adopted systematic nomenclature has existed for yeast protein-coding genes, or ORFs, as many yeast researchers call them. Readers of the last SGD newsletter will recall that, earlier this year, SGD adopted a new systematic nomenclature for the entire annotated complement of ncRNAs.
We have just put into place a new systematic nomenclature for S. cerevisiae genes that are not found in the reference genome of strain S288C (“non-reference” genes). This new systematic nomenclature is similar to, but distinct from, that used for ORFs and that used for ncRNAs. Non-reference genes are designated by a symbol consisting of three uppercase letters and a four-digit number, as follows: Y for “Yeast”, SC for “Saccharomyces cerevisiae”, and a four-digit number corresponding to the sequential order in which the gene was added to SGD. We currently have 55 of these genes in SGD, some of which are old favorites like MAL21/YSC0004 and MATA/YSC0046, while others are more recent additions like XDH1/YSC0051. Going forward, as evidence is published pointing to other S. cerevisiae genes not present in the S288C reference genome, they will be added to the annotation using the next sequential number available. We already have 15 more of these YSC0000 names reserved by researchers and awaiting publication.
If you have some non-reference genes for which these names would be appropriate, please let us know!
New links to AlphaFold 3D Predicted Protein Structure Database
Would you like to see the shape of your protein?
SGD now contains links to AlphaFold in the Resources sections of the Summary, Protein, and Homology pages for every gene.
{kind=link}
- The links through SGD give quick access to EMBL’s European Bioinformatics Institute (EMBL-EBI), which offers a new, highly accurate tool for predicting protein structure with speed and clarity.
- Given a peptide sequence for an uncharacterized protein, AlphaFold will model predicted domains and provide relative confidence levels for each portion of the prediction.
- The predicted domains can then be compared to known protein structures (using a tool such as PDBeFold) to seek matches to characterized protein families.
- Whether or not a family is identified, the comparison will yield clues to protein function to help design the next experiments.
DIOPT Orthologs and New Queries in YeastMine
We recently replaced HomoloGene, Ensembl, TreeFam and PANTHER homology datasets in YeastMine with homology data from DIOPT (DRSC integrative ortholog prediction tool). DIOPT integrates orthology predictions from multiple sources, including HomoloGene, Ensembl, TreeFam, and PANTHER. Using the Gene->Non-fungal and S. cerevisiae Homologs pre-generated query, you can look for DIOPT homologs for a single or multiple yeast genes. The results table provides identifiers and standard names for the yeast and homologous genes, as well as organism and predictive score information. As with other YeastMine templates, results can be saved as lists and analyzed further.
Pre-generated queries for human homolog(s) of your favorite yeast gene and their corresponding disease associations remain largely unchanged. You can begin with your favorite human gene or disease keyword and retrieve the yeast counterparts of the relevant gene(s). As an example, you can search for the S. cerevisiae homologs of all human genes associated with disorders that contain the keyword “diabetes” (view search). The results table provides identifiers and standard names for the yeast and human genes, OMIM gene and disease identifiers and name, as well as predictive algorithm sources and scores.
Alliance of Genome Resources – Recent Release
The Alliance of Genome Resources, a collaborative effort from SGD and other model organism databases (MOD), released version 4.1 this past August. Notable improvements and new features include:
- Human and model organism high throughput (HTP) variant data
- Human variants are imported from Ensembl
- Model organism HTP variants are submitted by Alliance members (FlyBase, RGD, SGD, Wormbase) or imported from EVA (MGI and ZFIN).
- Added HTP variants to the Alleles and Variants table on gene pages (e.g. rat Lepr Gene page) and to the table on the Alleles and Variants Details page (e.g. rat Lepr Alleles and Variants Details.
- Created a report page for Human and model organism HTP variants (e.g. human variant rs1041354454).
- Expanded Allele Category in search to “Allele/Variant” and added a search for HTP variants.
- On Gene Pages, a new Pathways widget displays via tabs:
- Reactome models of pathways for human gene products as well as inferred pathways for model organism genes based on orthology to human genes.
- Reactome reactions for gene products (e.g. human TP53 Gene page)
- Gene Ontology Causal Activity Models (GO-CAMs). These provide a framework to represent a biological system by linking together multiple GO annotations. PMID:31548717 (e.g. worm nsy-1 Gene page).
- Experimental conditions are include for Disease and Phenotype data in tables on Gene, Allele, and Disease pages (e.g. zebrafish scn1lab Gene page).
- AllianceMine added Orthologs, and Allele and Variants (low throughput) data types to this release. You can now query for these data types via pre-made template queries.
- The Alliance Community Forum is released. The Forum permits discussions across six model organism communities—flies, mice, yeast, rats, worms, and zebrafish. More details will follow.
Upcoming Conferences and Courses
- Fungal Genetics – the premier meeting for the international community of fungal geneticists
- Asilomar Conference Grounds, Pacific Grove, California (and Online)
- March 15 – 20, 2022
- 36th International Specialised Symposium on Yeasts (ISSY36) – Yeast Sea to Sky – Yeast in the Genomics Era
- University of British Columbia, Vancouver
- July 12 – 16, 2022
- CSHL Yeast Genetics & Genomics – modern, intensive laboratory course that teaches students full repertoire of genetic and genomic approaches
- Cold Spring Harbor Laboratory, NY
- July 26 – August 15, 2022
- Yeast Genetics Meeting – the premier meeting for students, postdoctoral scholars, research staff, and principal investigators studying various aspects of eukaryotic biology in yeast
- University of California, Los Angeles
- August 17 – 21, 2022
Gene Ontology Consortium Fall 2021 Meeting
From October 12-14, SGD biocurators attended the Gene Ontology Consortium’s Fall Meeting with participants from around the world. The goal of these meetings is to bring together data scientists with diverse backgrounds (curators, programmers, etc.) for lively discussions regarding how to better capture, curate, analyze, and serve data to researchers, educators, students, and other life science professionals. Our goal in participating in these meetings each year is to find ways to make SGD even better for you!
Discussion topics included, but were not limited to:
- LitSuggest – web-based system for biomedical literature recommendation and curation
- ECO, Evidence and Conclusions Ontology – terms used to describe types of evidence and assertion methods
- PAINT, Phylogenetic Annotation and INference Tool from PANTHER – orthology between reference genome genes and human disease genes
Happy Holidays from SGD!

We know that 2021 has been another challenging year for everyone. Our thoughts go out to all those who have been impacted by recent events. We wish you and your family, friends, and lab mates the best during the upcoming holidays.
Stanford University will be closed for two weeks starting December 20, and will reopen on January 3rd, 2022. Although SGD staff members will be taking time off, the website will be up and running throughout the winter break, and we will resume responding to user requests and questions in the new year.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Categories: Newsletter